我最近在Embedded Linux Conference Europe 2010 上做了一个演讲,题为高性能内存系统的软件影响。这个标题是我偷偷摸摸(而且相当成功)的方式,让人们参加一个真正关于内存访问(重新)排序和barriers的演讲。我现在想就这个话题发表几篇文章。在这篇文章中,我将介绍一些概念并解释它们背后的原因。在以后的帖子中,我将跟进一些实际示例。
The Sequential Execution Model 顺序执行模型
在美好的过去,计算机程序在实践中的行为方式几乎与你本能地期望它们查看源代码的方式相同:
- 事情以程序中指定的方式发生。
- 事情按照程序中指定的顺序发生。
- 事情发生在程序中指定的次数(不多也不少)。
- 事情一次一个地发生。
在现代计算机体系结构中,这种怀旧的幻想有时被称为顺序执行模型。为了使现有的程序和编程模型保持功能,即使是最极端的现代处理器也会试图从执行程序内部保留顺序执行的错觉。但是,在您的脚下将发生许多无法从处理器外部隐藏的事情。
Reality 现实情况
然而,现实情况是,为了提高性能(在速度和功率方面),正在系统的许多不同级别执行许多优化。
编译器优化
优化编译器可以大量重构代码,以隐藏管道延迟或利用微体系结构优化。它可以决定更早地移动内存访问,以便在需要该值之前有更多的时间完成,或者稍后移动内存访问,以便平衡通过程序的访问。在高度流水线化的处理器中,编译器实际上可能会重新排列各种指令,以便在需要其结果时提供先前指令的结果。
通常用于解释该问题的经典示例如下:
int flag = BUSY;
int data = 0;
int somefunc(void)
{
while (flag != DONE);
return data;
}
void otherfunc(void)
{
data = 42;
flag = DONE;
}
假设上面的代码在两个单独的线程中运行, 线程 A 调用 otherfunc() 来更新值并指示已完成的操作, 线程 B 调用 somefunc() 等到完成信号到达后再返回变量数据的值。 C 语言规范中没有任何内容可以保证 somefunc() 在开始轮询 flag 值之前不会生成读取数据的代码。这意味着 somefunc() 返回 0 或 42 是完全合法的。虽然有一些可能性可以解决此问题以进行代码生成,但这仍然不会阻止在硬件中完成的重新排序(见下文)。
Multi-issuing (更多问题???)
许多现代处理器支持每个时钟周期发出(和执行)多个指令。即使您显式地逐个放置了汇编指令,它们最终也可能并行发出和执行。
想象一下 Arm 程序集中的以下指令序列:
| Cycle | Issue |
|---|---|
| 0 1 2 3 4 5 6 |
add r0, r0, #1 mul r2, r2, r3 ldr r1, [r0] mov r4, r2 sub r1, r2, r5 str r1, [r0] bx lr |
在dual-issuing 处理器上,此序列实际上可能按如下方式执行:
| Cycle | Issue0 | Issue1 |
|---|---|---|
| 0 1 2 3 |
add r0, r0, #1 ldr r1, [r0] sub r1, r2, r5 str r1, [r0] |
mul r2, r2, r3 mov r4, r2 mov r4, r2 bx lr |
在此示例中,cycle 2 中的 Issue1 不会发出任何内容,因为后续指令需要从发出到 Issue0 中的子指令的结果。该指令改为在第 3 cycle;与子例程返回并行。
Out-of-order execution 乱序执行
第一个支持乱序执行的 Arm 处理器是 Arm1136J(F)-S,它允许非依赖加载和存储操作彼此无序完成。在实践中,这意味着缓存中未命中的数据访问可以被缓存中命中(或未命中)的其他数据访问所取代,只要它们之间没有数据依赖关系。它还允许加载存储指令在没有数据依赖关系的情况下(例如,加载为后续加载或存储提供地址)的数据处理指令无序完成。
快进几年到Cortex-A9。在许多情况下,该处理器支持大多数非依赖指令的无序执行。当指令因等待前一条指令的结果而停止时,内核可以继续执行不需要等待未满足的依赖项的后续指令。
请考虑以下代码片段,其中包含几个指令,可能需要多个周期才能将结果提供给后续指令。在多个架构上,mul 和 ldr 都需要多个周期才能获得结果。在这种情况下,我们假设每个周期有 2 个周期。
add r0, r0, #4
mul r2, r2, r3
str r2, [r0]
ldr r4, [r1]
sub r1, r4, r2
bx lr
如果我们在按顺序处理器上执行此代码,则执行将如下所示:
| Cycle | Issue |
|---|---|
| 0 1 2 3 4 5 6 7 |
add r0, r0, #4 mul r2, r2, r3 *stall* str r2, [r0] ldr r4, [r1] *stall* sub r1, r4, r2 bx lr |
如果我们在无序处理器上执行它,我们可能会看到更像:
| Cycle | Issue |
|---|---|
| 0 1 2 3 4 5 |
add r0, r0, #4 mul r2, r2, r3 ldr r4, [r1] str r2, [r0] sub r1, r4, r2 bx lr |
通过允许 ldr 在我们等待 mul 完成时执行,以便 str 可以继续,我们还给了 ldr 在需要其值之前完成的更多时间。
Speculation
Speculation 可以简单地描述为核心执行或开始执行指令,然后才知道是否应该执行该特定指令。这意味着,如果条件解决,推测是正确的,结果将更快可用。例如,当代码在 Arm or Thumb instruction sets中使用通用条件执行时,或者当核心遇到条件分支指令时。然后,内核可以推测性地执行条件指令,或条件分支指令之后的指令。如果它这样做,它必须确保如果猜测被证明是不正确的,它这样做的任何迹象都被抹去。
就内存加载指令而言,speculation 可以走得更远。可以推测性地发出来自可缓存位置的加载,这反过来可能导致从外部存储器复制该位置,从而可能逐出现有缓存行。许多现代处理器更进一步,监视执行的数据访问以检测模式,甚至在指令进入处理器管道之前将该模式中的后续地址引入缓存。
Load-Store Optimizations 负载存储优化
高性能系统中的外部存储器访问往往具有明显的延迟 -;即使内核:内存时钟比高达2:1,实际的数据传输也只能在多次设置时间周期后进行。这可以是 5- 之间的任何位置;50个总线时钟周期,主要取决于系统的功率曲线-;缓存或桥接正在路上,在此基础上增加了额外的周期。由于内核与内存时钟比不太有利,这种影响会成倍增加。
为了减少这些延迟的影响,处理器非常尝试优化其内存访问,以(如果可能)通过在每个事务中写入更多数据来减少事务数量 -;使用突发传输更长的数据流,仅具有单个事务的延迟。例如,这可能意味着对缓冲内存的多次写入可以合并到一个事务中。
多核 Cache一致性
使用多核处理器时,基于硬件的缓存一致性管理可能会导致缓存行在内核之间透明地迁移。这可能会导致不同的内核以不同的顺序查看对缓存内存位置的更新。
举一个具体的例子:上面的somefunc()和otherfunc()的例子在多核SMP系统中执行时还有另一个潜在的方面。如果两个线程在不同的内核上执行,那么硬件缓存一致性管理、推测和乱序执行的组合意味着不同内核可能会以不同的方式看到内存访问的顺序。
简而言之,硬件缓存一致性管理意味着缓存行可以在内核之间移动,以便在访问它们的任何地方可用。由于支持无序的处理器可以在等待另一个加载(或存储)的结果完成的同时从缓存中加载一个内存位置,因此完全允许执行 somefunc() 的核心在 flag 的值实际更改为 DONE 之前推测加载数据的值 - 即使这不是指令在编译应用程序中的顺序。
外部存储器系统
即使进入外部存储器系统,复杂性仍在继续。
为了在具有许多总线主站(代理)的系统中实现高性能,可以在多层系统中配置互连。这实际上意味着不同的代理(或主站)可以具有到系统中各种设备(或从站)的不同路由。此外,内存控制器等外围设备可能具有多个从属接口,允许多个代理同时访问它。
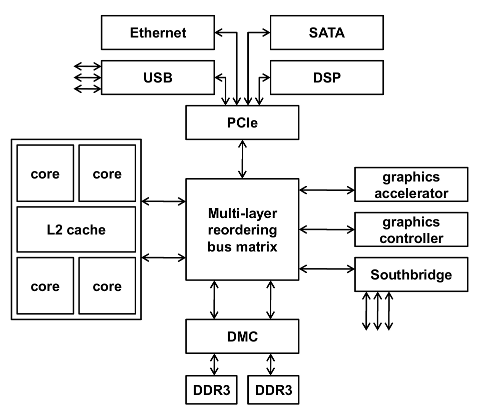
最后,允许缓冲的内存事务几乎可以在过程中的任何时候都是如此,并且可能不止一次。这可能会导致来自不同主节点的访问在不同场合需要不同的时间才能完成。
结论
在现代计算机系统中,很多事情的发生顺序与人们直觉假设的顺序不同 - ;并非系统中的每个代理都会就该顺序达成一致。在下面的帖子中,我将介绍这在实践中意味着什么以及您可能需要做些什么。
您可以通过单击下面的链接阅读本博客系列的第 2 部分。